I shipped an AI cooking app to zero users. Supabase wasn't the problem.
![]()
Supabase didn’t kill my project. I did, by skipping the marketing. Three months solo, October 2025 through mid-January 2026, zero downloads at launch, project shut down. The stack held up. The product didn’t.
YumCrush was Tinder for home cooking — swipe recipes, get an AI assistant to walk you through the one you matched with. On top of that: a fridge inventory by weight and count, a shared shopping list, a todo list, a family chat, and an AI cooking assistant tied to each recipe. The swipe was the core idea; everything else compounded on it.
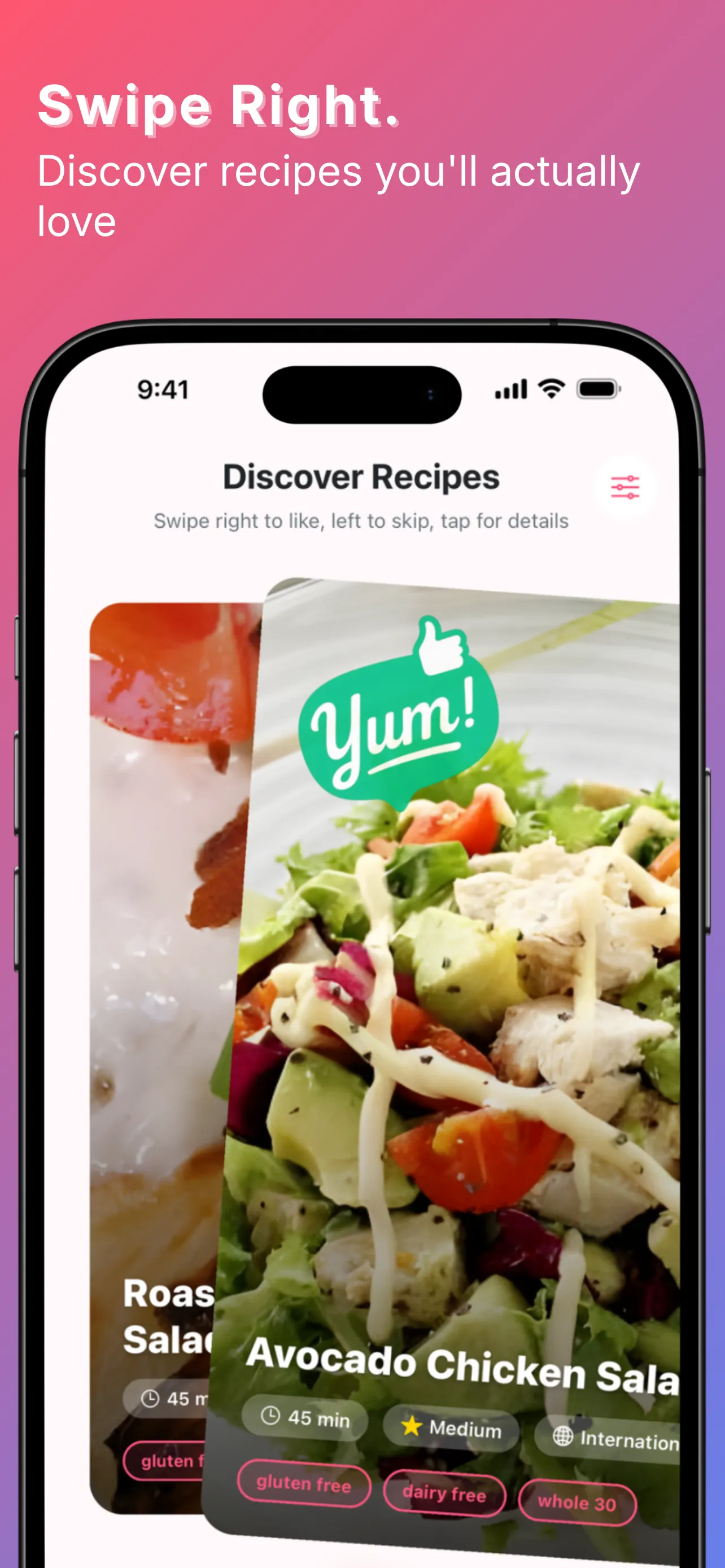
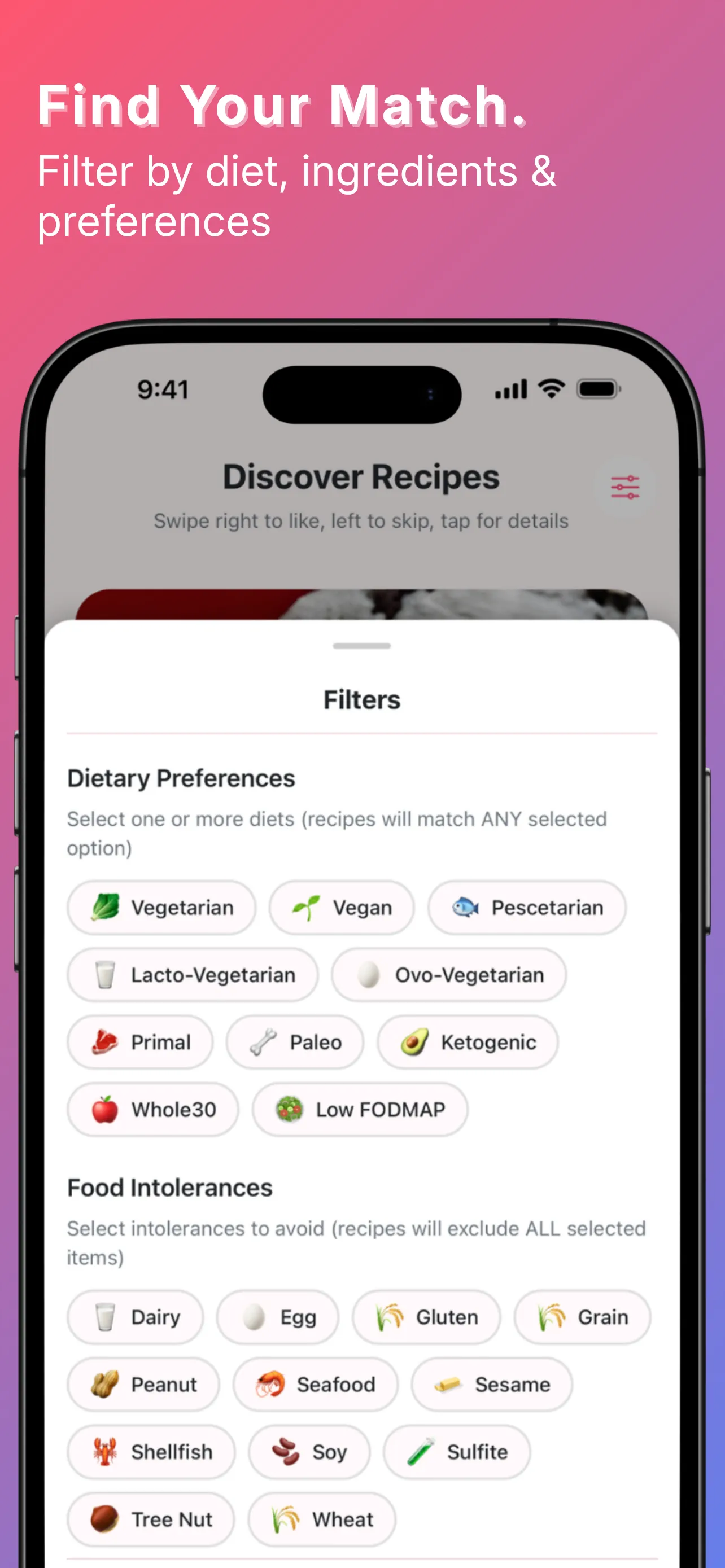
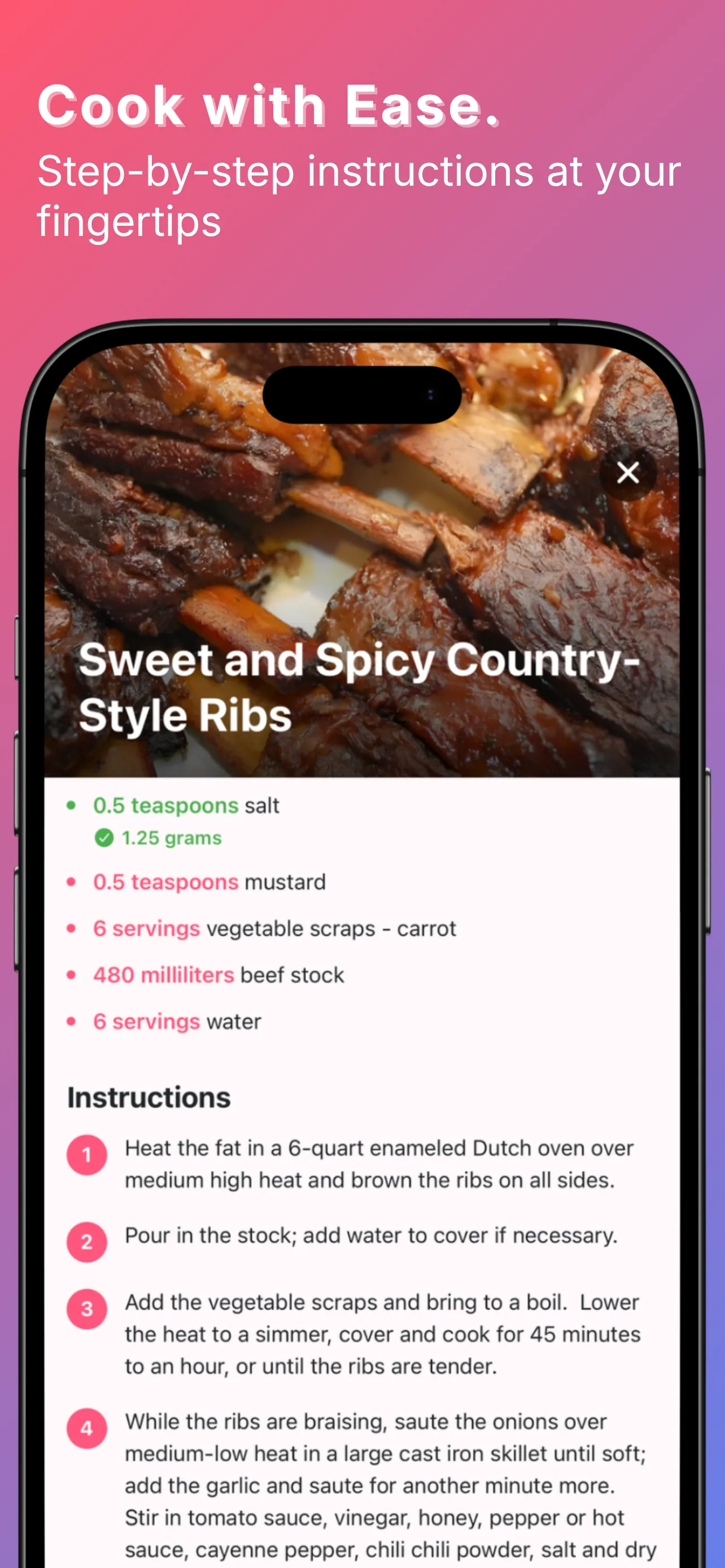
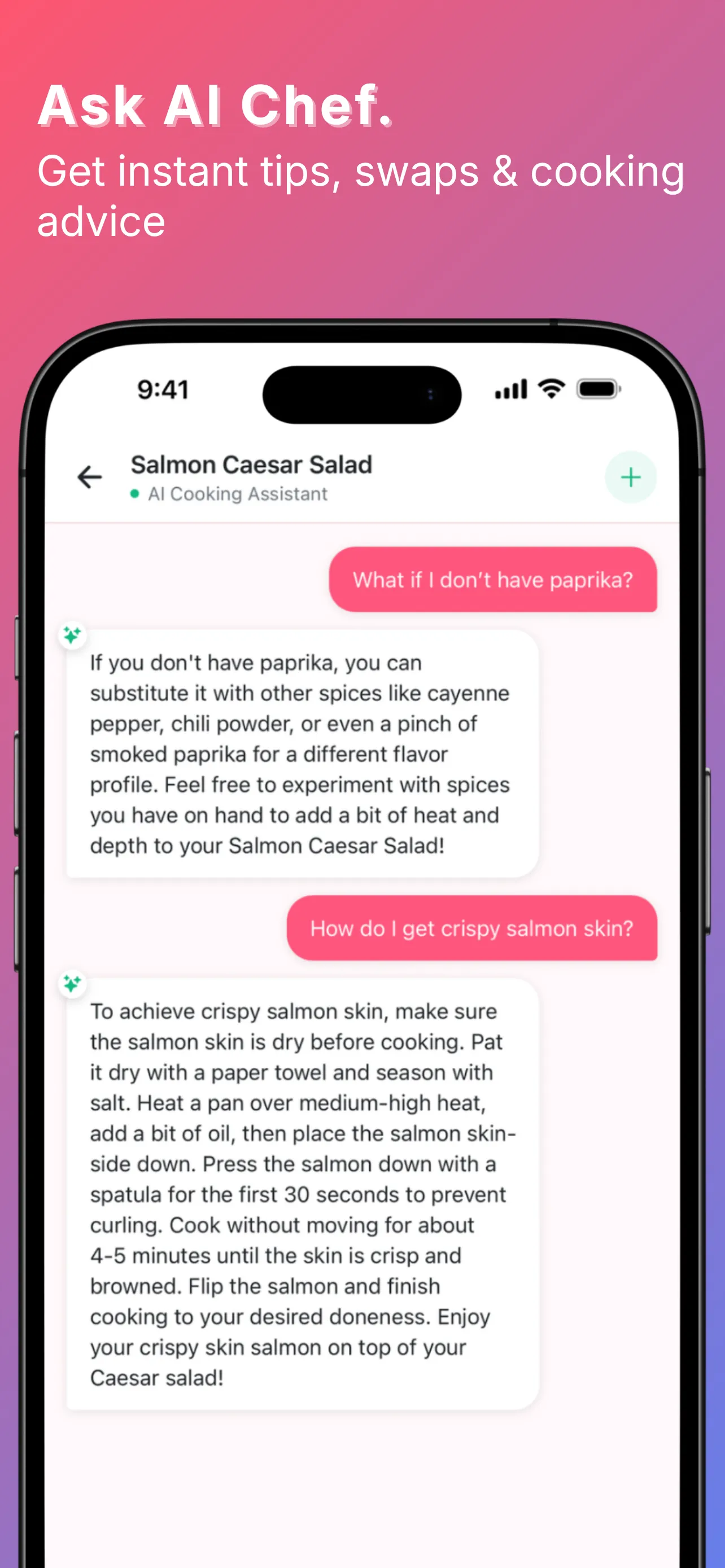
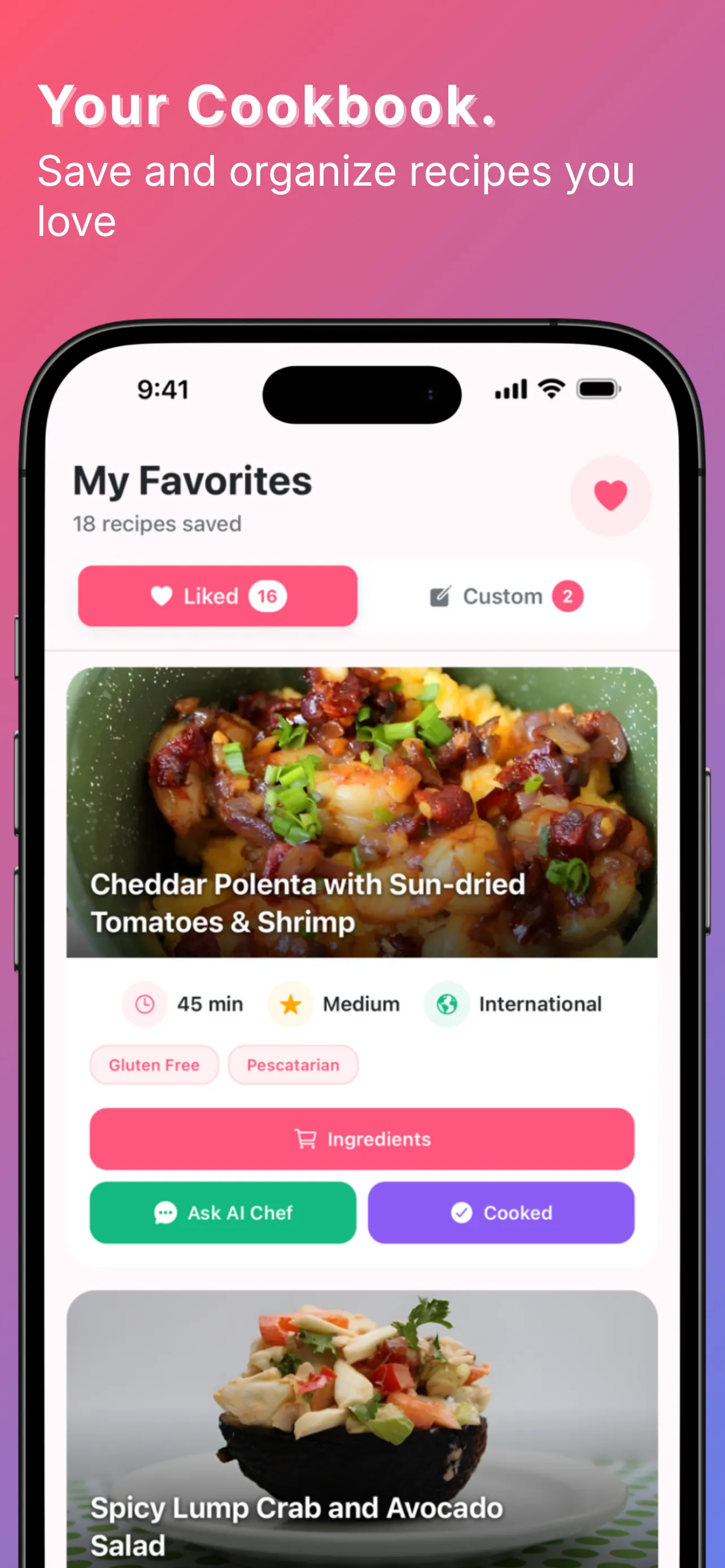
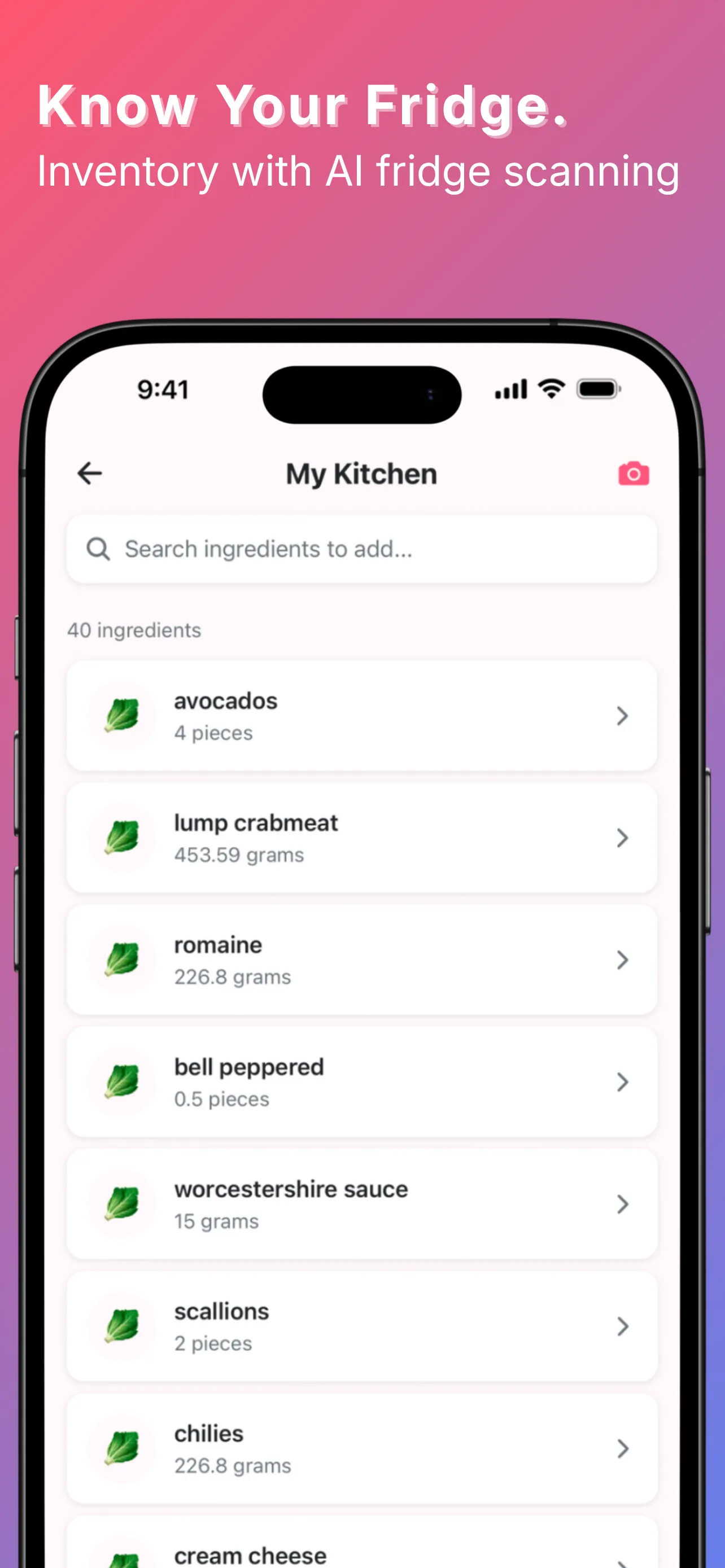
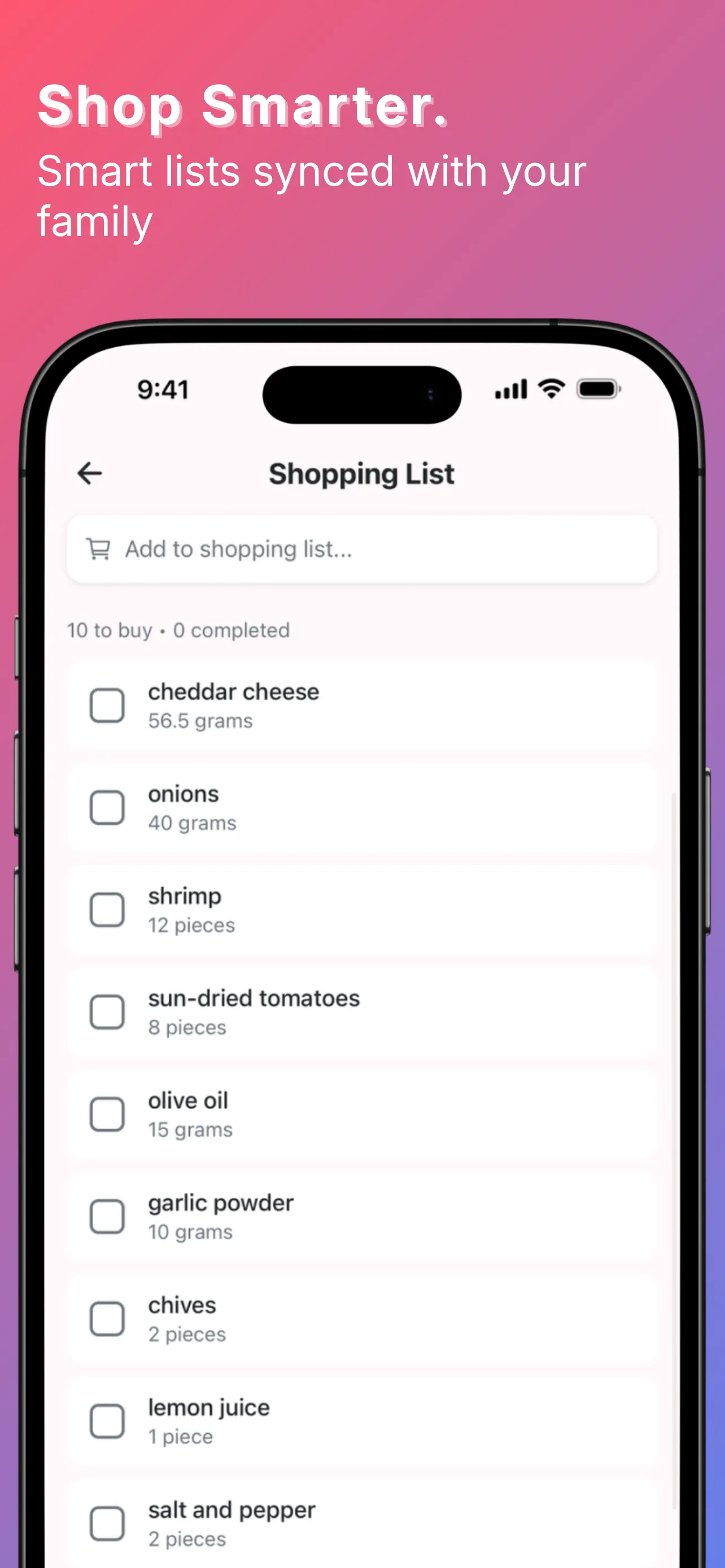
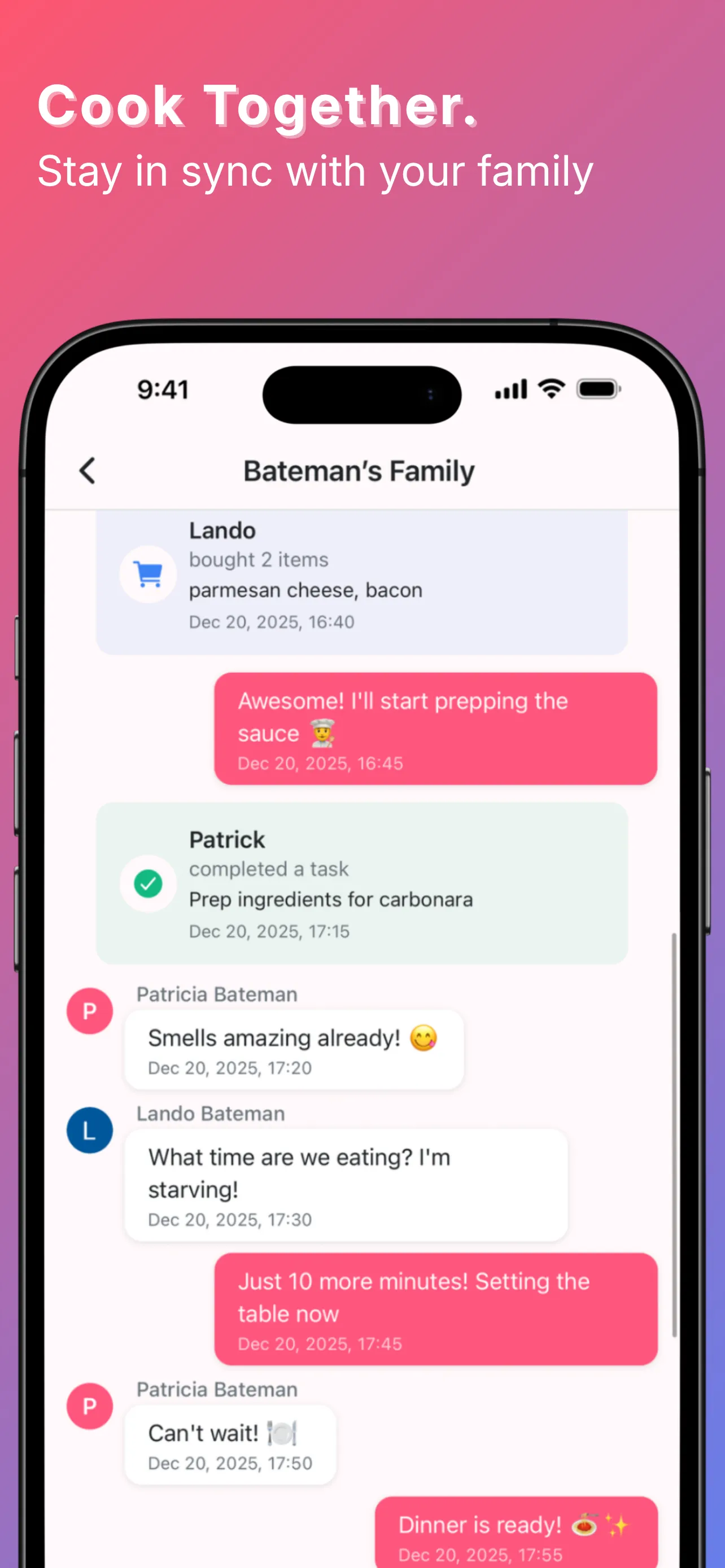
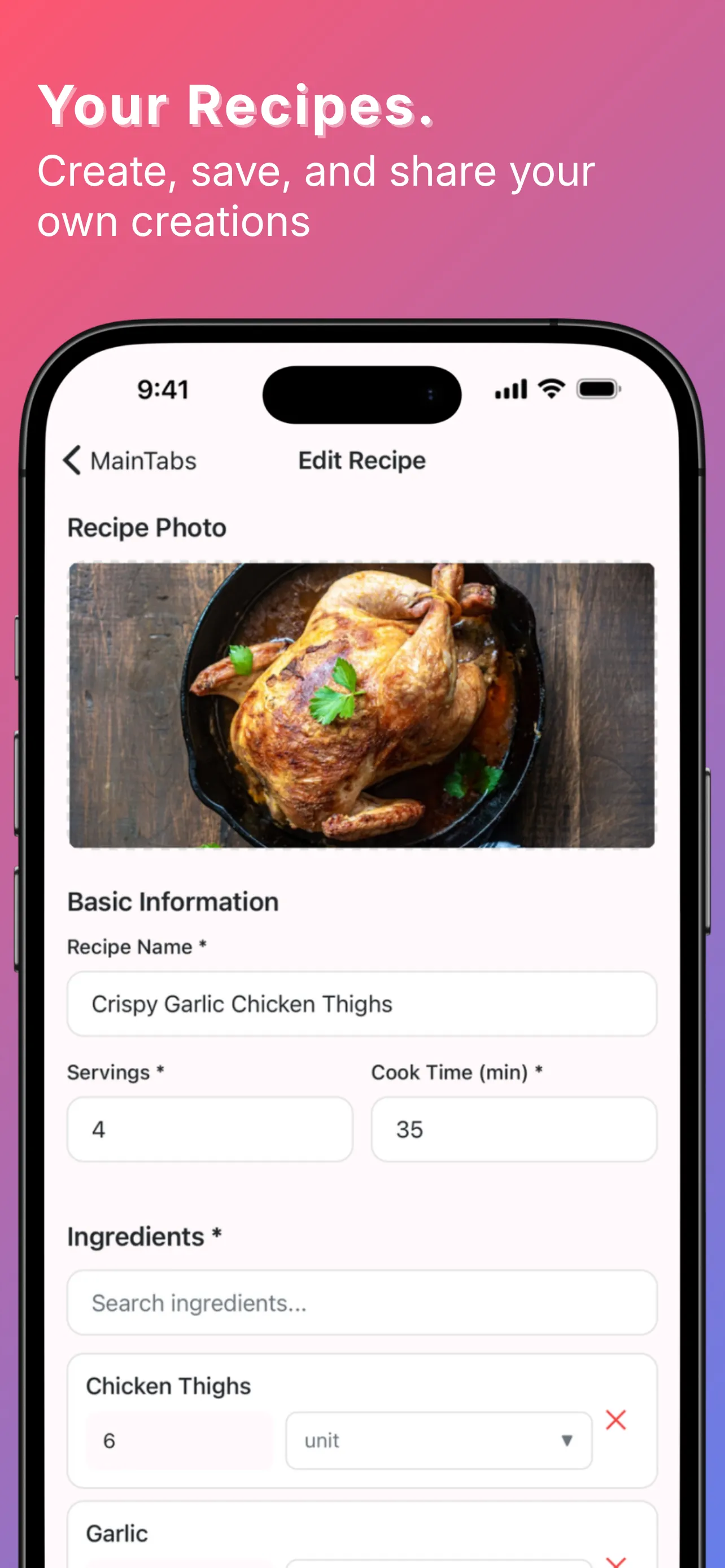
By the numbers, the backend shipped:
- 23 tables behind 41 migrations
- 16 Edge Functions on Deno
- Row Level Security on every user-owned table
- Realtime on five tables (chat, inventory, shopping list, todo, family membership)
- Three Storage buckets (avatars, recipe photos, chat images)
I wrote almost none of that code. I designed the system and Claude Code implemented it. I’ll come back to that.
What Supabase replaced
I’m a backend engineer. I could have stood all of this up myself — auth service, RLS layer, push fanout, storage, the whole pipeline. I didn’t. Solo, three months, hard deadline: every week spent rebuilding plumbing is a week not spent on the actual product. Supabase was a deliberate tradeoff for calendar time, not a workaround.
Auth. Apple and Google OAuth wired up in an evening. Email/password with confirmation. Password reset emails that branch based on auth_provider — if you signed up with Google, the password reset email tells you to go back to Google instead of dropping you on a broken flow.
RLS over Postgres. Every table — swipes, inventory, custom recipes, family chats — was guarded at the database. No “did I forget to check ownership in this endpoint.” A typical optimized policy looked like this:
CREATE POLICY "Users can read own dietary preferences" ON dietary_preferences
FOR SELECT
USING (user_id = (SELECT auth.uid()));The (SELECT auth.uid()) wrap is the part the Supabase linter yells at you about. Without it, auth.uid() is called per row. Wrapped, the planner caches it once per query — an effectively free 100x speedup on any query that returns more than a few rows.
For family-scoped data — inventory shared across a household, chat messages, custom recipes — the pattern was an EXISTS subquery against family_members:
CREATE POLICY "Members can read family inventory" ON inventory_items
FOR SELECT
USING (
EXISTS (
SELECT 1 FROM family_members
WHERE family_members.family_id = inventory_items.family_id
AND family_members.user_id = (SELECT auth.uid())
)
);That single policy replaces a middleware function, a service-layer check, and the unit test for “what happens when user A asks for user B’s family inventory.” It runs in the same query that fetches the rows. There is no second roundtrip.
Realtime. Family chat and the shared shopping list are subscriptions. The client opens a channel on a table, the UI updates when a row changes. No socket server, no queue, no fanout code.
Edge Functions. Anything that needed a secret or a stable IP lived in Deno: a Spoonacular proxy with a 30-day Upstash Redis cache (and a Firebase Analytics ping that logged $0.0005 / point so I could watch the API bill), OpenAI Vision for fridge scans, streaming GPT for the recipe assistant, and Replicate’s Real-ESRGAN for image upscaling.
The piece I keep telling people about is the chat push pipeline. A new chat message inserts a row. A Postgres trigger fires pg_net.http_post to an Edge Function. The function fetches every family member except the sender, pulls their Expo push tokens, and fans out the notification. End to end:
CREATE OR REPLACE FUNCTION public.trigger_chat_push_notification()
RETURNS TRIGGER AS $$
BEGIN
PERFORM net.http_post(
url := function_url,
headers := jsonb_build_object('Content-Type', 'application/json'),
body := jsonb_build_object(
'type', 'INSERT',
'table', 'chat_messages',
'record', row_to_json(NEW)
)
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql SECURITY DEFINER;
CREATE TRIGGER chat_message_push_notification
AFTER INSERT ON public.chat_messages
FOR EACH ROW
EXECUTE FUNCTION public.trigger_chat_push_notification();No queue, no worker, no cron. The database is the orchestrator. You either find this elegant or unsettling. I find it elegant for a project of this size.
Storage. Avatars, custom-recipe photos, chat images, upscaled recipe photos (more on those below). Per-bucket RLS using path prefixes ({user_id}/... for avatars, {family_id}/... for chat images) so the SELECT policy could be public while writes stayed scoped.
I stayed on the free tier for the entire build and only paid right before release. Not because of traffic — because of the upscaling pipeline. $30/month, almost entirely image storage.
I never hit a Supabase wall during development. No outages, no API gotchas, no “we have to move off this.” For a solo project, that’s worth more than any single feature.
The image pipeline (the one piece I’d keep)
Spoonacular’s photos were two problems at once: dull framing and low resolution. I couldn’t fix the framing, so I went after the resolution.
When a recipe surfaced for the first time in the entire system, the client showed the original low-res photo immediately — no spinner, no delay — and in the background called an Edge Function that ran the source URL through Real-ESRGAN on Replicate, uploaded the 2x result to Storage, and wrote a row in upscaled_images. When the upscale came back, the client cross-faded the new image over the old one in place. The next time any user on the platform saw the same recipe, the upscaled version came back on the first paint.
The whole thing hinged on the cache key. SHA256 of the source URL, not of the user, not of the recipe ID. Replicate cost was paid once per unique image, ever, across every user.
const hashBuffer = await crypto.subtle.digest(
'SHA-256',
new TextEncoder().encode(source_url)
);
const source_hash = Array.from(new Uint8Array(hashBuffer))
.map(b => b.toString(16).padStart(2, '0'))
.join('');
const { data: cached } = await supabase
.from('upscaled_images')
.select('upscaled_url, access_count')
.eq('source_hash', source_hash)
.eq('status', 'completed')
.single();
if (cached) {
// Cache hit: 0ms upscale, bump access counters and return.
await supabase.from('upscaled_images').update({
accessed_at: new Date().toISOString(),
access_count: cached.access_count + 1,
}).eq('source_hash', source_hash);
return cached.upscaled_url;
}
// Cache miss: call Replicate, upload to Storage, insert row.Files landed at upscaled-images/{source_hash}/{timestamp}_2x.jpg with Cache-Control: 31536000 (one year), so the CDN held a copy too. Three layers of cache stacked: client expo-image memory/disk, CDN edge, Supabase Storage origin. A repeat view was effectively free.
The fallbacks were aggressive on purpose. 15-second timeout client-side via AbortController. Replicate down? Return the original URL. Storage upload fails? Return the original URL. The user never saw a broken image — at worst they saw what Spoonacular gave them.
const controller = new AbortController();
const timeoutId = setTimeout(() => controller.abort(), 15_000);
try {
const { data } = await supabase.functions.invoke('upscale-image', { body });
return data.upscaled_url ?? sourceUrl;
} catch {
return sourceUrl; // silent fallback
} finally {
clearTimeout(timeoutId);
}The irony is the rest of this post. The pipeline is clean — global cache, graceful degradation, amortized cost, no broken images. The decision to build it was wrong. The recipe data was the problem; the pixel count wasn’t. Sharper photos of a boring recipe are still a boring recipe. The $30/month I paid was the Storage bill for a cache I built to paper over a bad API.
I’d keep the pipeline pattern for the next project. I just wouldn’t aim it at the same target.
Where Claude Code carried, and where it broke
I wrote almost no code on this project. I designed the system, reviewed diffs, ran the app, and let Claude implement. Most of the build ran on Sonnet 4.5 — the strongest coding model when I started in October 2025 — and I switched to Opus 4.5 for the last six weeks once it shipped on November 24. I picked up React Native this way without ever typing a useState myself.
It worked, but the model’s context window was too small for a codebase this size. By the last month the symptoms were obvious:
- The same component pattern reimplemented three times because earlier files had aged out of context.
- Boilerplate creep — every new screen pulled in a slightly different version of the same setup.
- UI bugs were the hardest. At the time there was no good way for the agent to actually see the screen. I’d describe the glitch in words and hope.
Then I stopped reviewing carefully around month three. That’s on me, not the model. The result is a 1500-line FavoritesScreen.tsx, ~800 stray console.log calls, and a handful of god-files. I broke my own rule: keep things modular and compact, for agents and for humans reading the code later. Compact files aren’t a style preference — they’re how you keep an agent productive on a long project. A 1500-line file does not fit in working memory; the model regenerates context every turn, and the work degrades.
On Opus 4.7 or GPT-5.5 the same project would ship faster and cleaner. The constraint was never Supabase — it was how much of the codebase the agent could hold in its head at once.
I also used spec-kit for spec-driven development. Each feature got a spec.md, a plan.md, a tasks.md, and data-model.md before any code was written. The repo still has 17 of those folders, and the structure did push back when the agent drifted. Spec-kit has moved on since I used it, and so have the models. I want to try the current version on a real project with a modern model driving — I just haven’t gotten around to it yet.
Why it actually failed
Zero downloads is a marketing failure, not a backend failure. In order:
- No marketing. I started thinking about it at launch instead of during the build.
- The recipe API returned unappetizing photos and dull recipes. The whole product hinged on “the swipe felt fun.” It didn’t.
- Burnout and lost belief — both downstream of (1) and (2). I cached upscaled images instead of fixing the recipe data.
- The target user is real, but I never validated they’d open a fifth recipe app instead of the four they already ignore.
When to reach for Supabase
For any solo or small-team project where calendar time matters more than owning every layer — yes, every time. Even when you can write the backend yourself, Supabase compresses weeks of plumbing (auth, RLS, realtime, storage, edge functions) into hours. RLS at the database is the part that scales the furthest without ceremony, and the rest of the platform earns its keep on the first day. The infra time you save goes straight into the product, which is the only thing anyone judges you on.
For larger systems with unusual data shapes or multi-tenant requirements that don’t fit Postgres-row-level boundaries, you’ll outgrow it — but that’s the kind of decision you make once you have users, not before.
The shipping lesson is older and dumber than the stack: research demand before you build, start marketing during the build. The cleanest backend in the world still ships to zero users if no one knows it exists.